protectedbooleantryReleaseShared(int releases) { // Decrement count; signal when transition to zero for (;;) { intc= getState(); if (c == 0) returnfalse; intnextc= c - 1; if (compareAndSetState(c, nextc)) return nextc == 0; } }
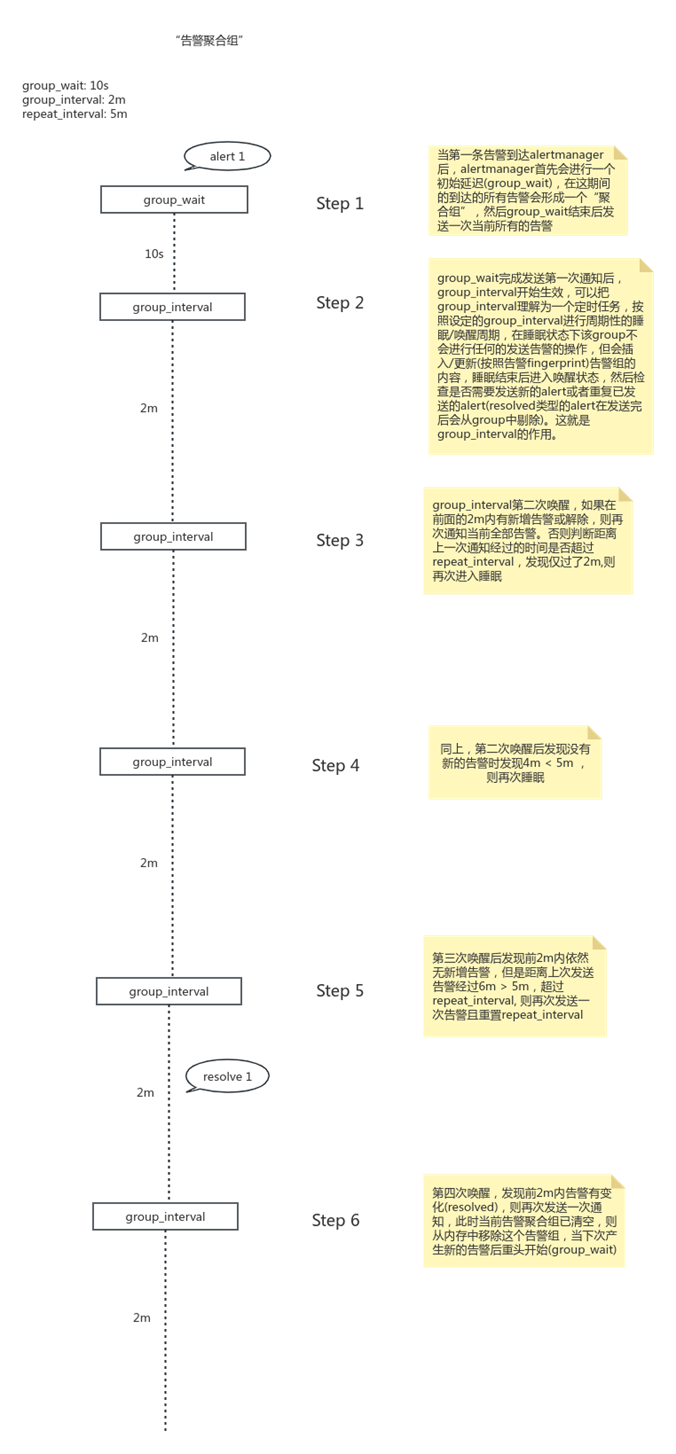
# How long to initially wait to send a notification for a group # of alerts. Allows to wait for an inhibiting alert to arrive or collect # more initial alerts for the same group. (Usually ~0s to few minutes.) [ group_wait:<duration>|default=30s ] # How long to wait before sending a notification about new alerts that # are added to a group of alerts for which an initial notification has # already been sent. (Usually ~5m or more.) [ group_interval:<duration>|default=5m ] # How long to wait before sending a notification again if it has already # been sent successfully for an alert. (Usually ~3h or more). # Note that this parameter is implicitly bound by Alertmanager's # `--data.retention` configuration flag. Notifications will be resent after either # repeat_interval or the data retention period have passed, whichever # occurs first. `repeat_interval` should not be less than `group_interval`. [ repeat_interval:<duration>|default=4h ]
// resolvedRetention is the duration for which a resolved alert instance // is kept in memory state and consequently repeatedly sent to the AlertManager. const resolvedRetention = 15 * time.Minute
Device Start End Sectors Size Type /dev/nvme1n1p1 2048 1026047 1024000 500M EFI System /dev/nvme1n1p2 1026048 2000408575 1999382528 953.4G Linux filesystem
title Arch Linux linux /vmlinuz-linux initrd /intel-ucode.img initrd /initramfs-linux.img options root=UUID=7a6f4b50-3914-4745-b907-a11a26258215 rw quiet splash vt.global_cursor_default=0
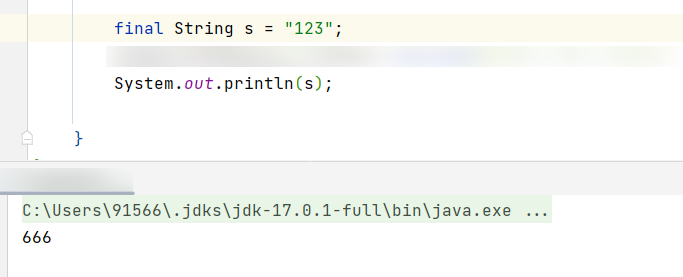
title可以随便写,意思就是当前系统的命名
linux 这里是linux的内核,通过bootctl install就已经把内核复制到了/boot下
Google Guava Cache是一种非常优秀本地缓存解决方案,提供了基于容量,时间和引用的缓存回收方式,他的优点是封装了get,put操作;提供线程安全的缓存操作;提供过期策略;提供回收策略;缓存监控。当缓存的数据超过最大值时,使用LRU算法替换。这一篇我们将要谈到一个新的本地缓存框架:Caffeine Cache。它也是站在巨人的肩膀上-Guava Cache,借着他的思想优化了算法发展而来。
// Implementation of library function gets() char *gets(char *s) { int c; char *dest = s; while ((c = getchar()) != '\n' && c != EOF) *dest++ = c; if (c == EOF && dest == s) returnNULL; *dest++ = '\0'; return s; } // Read input line and write it back voidecho() { char buf[8]; // Way to small!! gets(buf); puts(buf); }
这个分类不是具体锁的分类,而是看待并发同步的角度;悲观锁认为对于同一个数据的并发操作一定是会发生修改的(哪怕实质没修改也认为会修改),因此对于同一个数据的并发操作,悲观锁采取加锁的形式,因为悲观锁认为不加锁的操作一定有问题;乐观锁则认为对于同一个数据的并发操作是不会发生修改的,在更新数据的时候会采用不断的尝试更新,乐观锁认为不加锁的并发操作是没事的;由此可以看出悲观锁适合写操作非常多的场景,乐观锁适合读操作非常多的场景,不加锁会带来大量的性能提升,悲观锁在 java 中很常见,乐观锁其实就是基于 CAS 的无锁编程,譬如 java 的原子类就是通过 CAS 自旋实现的。
分段锁
实质是一种锁的设计策略,不是具体的锁,对于 ConcurrentHashMap 而言其并发的实现就是通过分段锁的形式来实现高效并发操作;当要 put 元素时并不是对整个 hashmap 加锁,而是先通过 hashcode 知道它要放在哪个分段,然后对分段进行加锁,所以多线程 put 元素时只要放在的不是同一个分段就做到了真正的并行插入,但是统计 size 时就需要获取所有的分段锁才能统计;分段锁的设计是为了细化锁的粒度。
A collection of methods for performing low-level, unsafe operations. Although the class and all methods are public, use of this class is limited because only trusted code can obtain instances of it. Note: It is the responsibility of the caller to make sure arguments are checked before methods of this class are called. While some rudimentary checks are performed on the input, the checks are best effort and when performance is an overriding priority, as when methods of this class are optimized by the runtime compiler, some or all checks (if any) may be elided. Hence, the caller must not rely on the checks and corresponding exceptions!
]]><p>共享内存是一种用于实现进程间通信(IPC)的方法,不同进程通过访问同一块内存区域实现数据共享和交互。每个进程可以将自身的虚拟地址映射到物理内存中的特定区域,当不同进程将相同的物理内存区域与各自的虚拟地址空间关联时,这些进程就能实现通过共享内存来完成IPC。若某进程更改了共享内存区的内容,其它进程都会觉察到该区域的更改。</p>进程通信之信号https://chaofan.xyz/posts/99134621.html2022-05-01T20:16:21.000Z2024-03-07T02:32:01.630Z在 Linux 中,理解信号的概念是非常重要的。这是因为,信号被用于通过 Linux 命令行所做的一些常见活动中。例如,每当你按 Ctrl+C 组合键来从命令行终结一个命令的执行,你就使用了信号。知道信号的基本原理是非常有用的。
概述
在 Linux 系统(以及其他类 Unix操作系统)中,信号被用于进程间的通信。信号是一个发送到某个进程或同一进程中的特定线程的异步通知,用于通知发生的一个事件。从 1970 年贝尔实验室的 Unix 面世便有了信号的概念,而现在它已经被定义在了 POSIX 标准中。
对于在 Linux 环境进行编程的用户或系统管理员来说,较好地理解信号的概念和机制是很重要的,在某些情况下可以帮助我们更高效地编写程序。对于一个程序来说,如果每条指令都运行正常的话,它会连续地执行。但如果在程序执行时,出现了一个错误或任何异常,内核就可以使用信号来通知相应的进程。
信号同样被用于通信、同步进程和简化进程间通信,在 Linux 中,信号在处理异常和中断方面,扮演了极其重要的角色。信号巳经在没有任何较大修改的情况下被使用了将近 30 年。
]]><p>在 Linux 中,理解信号的概念是非常重要的。这是因为,信号被用于通过 Linux 命令行所做的一些常见活动中。例如,每当你按 Ctrl+C 组合键来从命令行终结一个命令的执行,你就使用了信号。知道信号的基本原理是非常有用的。</p>vim常用配置https://chaofan.xyz/posts/2a71af52.html2022-05-01T00:28:21.000Z2024-03-07T02:32:01.630Z记录以下vim比较好用的配置,添加到~/.vimrc即可
Serial收集器是最基础、历史最悠久的收集器,在JDK1.3.1之前是HotSpot虚拟机新生代收集器的唯一选择。顾名思义,这是一个单线程收集器,它的”单线程“不仅仅说明它只会使用一个处理器或者一条收集线程完成垃圾收集工作,更重要的是它在进行垃圾收集时,必须暂停其他所有工作线程,直到它收集结束,”Stop The World“。
CMS(Concurrent Mark Sweep) 收集器是一种获取最短回收停顿时间为目标的收集器,目前很大一部分的Java应用集中在互联网网站或者基于浏览器的B/S系统的服务器上,这种应用通常较为关注服务的相应速度,系统系统缩短停顿时间,以给用户带来良好的交互体验。CMS收集器就非常符合这类应用的需求。
其中初始标记、重新标记这两个步骤仍然需要”Stop The World”。初始标记仅仅只是标记一下GC Roots能直接关联到的对象,速度很快;并发标记阶段就是从GC Roots的直接关联对象开始遍历整个对象图的过程,这个过程消耗时间长但是不需要停顿用户线程,可以与垃圾收集线程一起并发运行;而重新标记阶段则是为了修正并发标记期间,因用户程序继续运作而产生变动的那一部分对象的标记记录,这个阶段的停顿时间通常比初始标记长一些,但也远远小于并发标记阶段是时间;最后是并发求清除阶段,清理删除掉标记阶段判断的已经死亡的对象,由于不需要移动存活对象,所以这个线程也可以与用户线程同时并发。